Dashboard d'analyse corporelle
Le contexte
Samsung Health exporte des CSV bruts : formats de date incohérents selon la version de l'app, types numériques approximatifs, aucune visualisation native. Passer par une app tierce aurait signifié céder ses données de santé à un service externe. J'ai donc construit la pipeline moi-même — ingestion, traitement, dashboard — déployée sur mon infra perso et alimentée en continu depuis 2023.
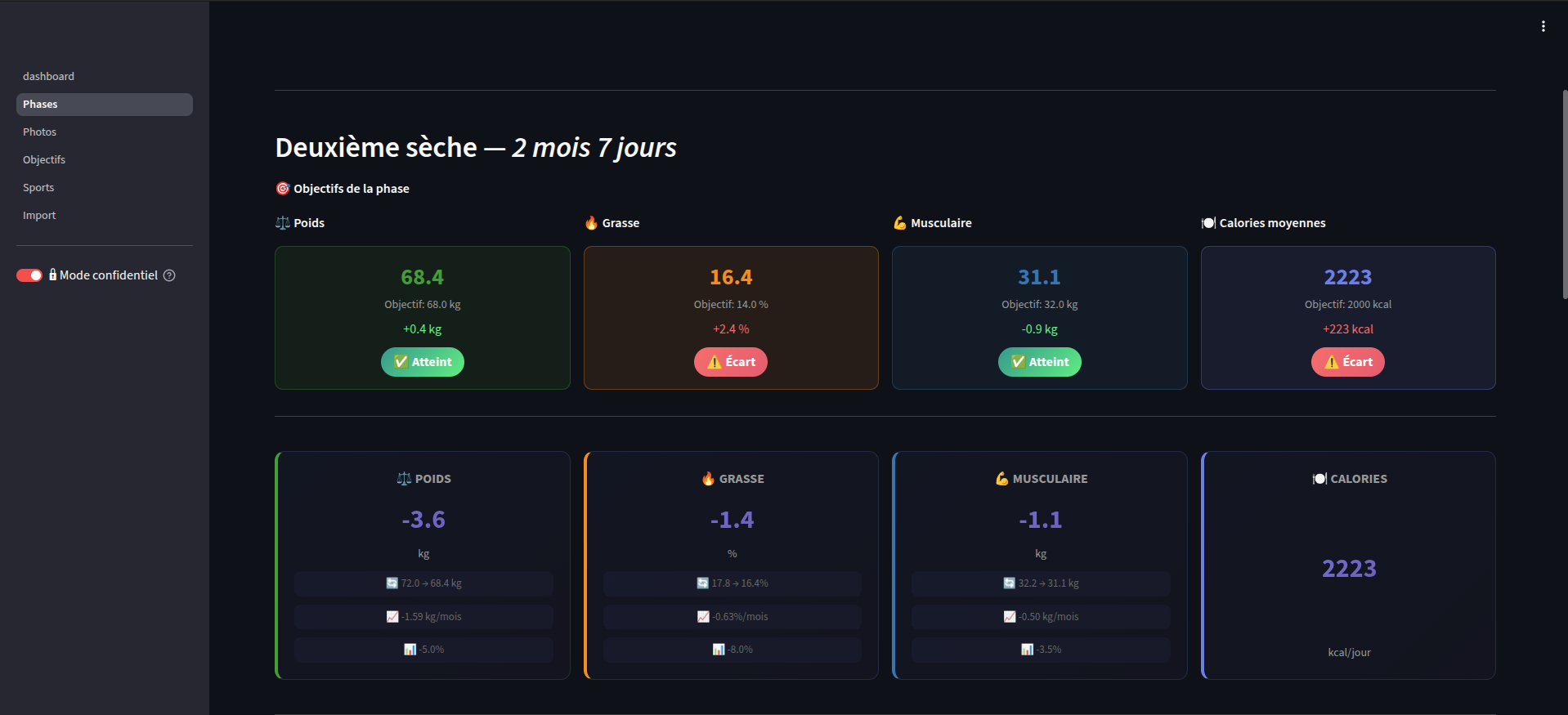
Les données couvrent le poids, la composition corporelle, les calories et les activités sportives, organisées en cycles explicites : phases de bulk, de cut, de maintien, chacune avec des objectifs chiffrés.
L'application
Le dashboard est une application Streamlit multi-pages : six vues distinctes correspondant chacune à un angle d'analyse. La vue principale présente une timeline des phases et l'évolution des métriques clés. Les vues Phases et Objectifs permettent un drill-down par cycle avec comparaison aux cibles. La vue Sports agrège les séances sous forme de heatmap calendrier. La vue Photos gère la galerie chronologique. La vue Import orchestre l'ingestion de nouveaux exports.
Chaque page est un module Python indépendant. Les données traversent la pipeline une seule fois au chargement — pas de requêtes successives côté UI.
Les défis techniques
Des exports qui ne sont pas fiables
Le premier problème est la qualité de la source. Les CSV Samsung Health varient selon la version de l'application : champs absents, dates tronquées, types numériques qui changent de format. Laisser la stdlib construire un objet datetime depuis une chaîne mal formée provoque une exception qui casse toute la ligne silencieusement. Le parser effectue donc une pré-validation explicite — extraction regex des composants, vérification des bornes calendaires — avant toute construction. La même logique s'applique aux types numériques : fallback explicite à zéro plutôt que laisser des valeurs manquantes se propager dans les agrégats Pandas en aval.
Modéliser des cycles, pas des snapshots
Les données brutes sont une série temporelle continue. L'enjeu est de les découper en phases cohérentes (bulk, cut, maintien) et de calculer des métriques par cycle : variation de poids absolue et relative, taux mensuel, évolution de masse grasse et musculaire, jours restants. Chaque phase est une dataclass immuable avec ses bornes et ses objectifs, chargée depuis un fichier de configuration versionné. Toutes les métriques sont calculées par filtrage vectorisé sur le dataframe — aucune boucle sur les lignes, seulement des opérations Pandas sur la plage de dates concernée.
Afficher des photos sans les exposer
Les photos de suivi corporel sont par nature privées. Les supprimer du dashboard aurait été la solution simple, mais inutile. Elles sont donc transformées à la volée avant affichage : floutage par filtre gaussien à rayon élevé, auto-détection de l'orientation (portrait ou paysage), redimensionnement avec préservation du ratio. Le résultat est consultable et partageable sans rien révéler.
La musculation est un cas à part
Samsung Health encode les types d'activité par des constantes entières non documentées. Tous les sports ont un identifiant fixe, sauf la musculation : elle n'a pas de type dédié dans l'export. Elle est identifiée indirectement, à la présence d'un champ reps dans les métadonnées JSON de la séance. Ce cas particulier est encapsulé dans le module sports_utils, qui centralise aussi le mapping des constantes vers des libellés lisibles. La heatmap d'activité est construite en deux étapes : agrégation Pandas par semaine et jour de semaine, puis encodage déclaratif Altair — ce qui évite de gérer les coordonnées manuellement.
Le déploiement
L'image Docker est construite sur python:3.11-slim et publiée automatiquement sur GitHub Container Registry à chaque push sur master. La configuration Docker Compose supporte les deux modes d'usage : standalone pour le dev local, et Docker Swarm pour la production, avec rolling update start-first et rollback automatique en cas d'échec. Les données sont stockées dans un volume nommé — elles survivent aux redéploiements. Des pre-commit hooks (Black, linters) garantissent que rien de cassé n'entre dans l'historique.
Ce qui reste imparfait
Il n'y a pas de tests automatisés sur le parsing : la robustesse s'est construite empiriquement, au fil des exports. Le fichier docker-compose.yml mélange la config standalone et Swarm dans le même fichier, ce qui est fonctionnel mais confus à maintenir. Streamlit tient bien pour ce cas d'usage, mais la gestion d'état via session_state atteint ses limites dès qu'on voudrait des interactions plus complexes.